linux.kernel - 26 new messages in 16 topics - digest
linux.kernel
http://groups.google.com/group/linux.kernel?hl=en
linux.kernel@googlegroups.com
Today's topics:
* video: add OpenCores VGA/LCD framebuffer driver - 1 messages, 1 author
http://groups.google.com/group/linux.kernel/t/6de4648d5dffb42a?hl=en
* re-shrink 'struct page' when SLUB is on. - 2 messages, 2 authors
http://groups.google.com/group/linux.kernel/t/d6d1692f51c2de27?hl=en
* linux-next: manual merge of the sound-asoc tree with the slave-dma tree - 1
messages, 1 author
http://groups.google.com/group/linux.kernel/t/6e92e09529c4927c?hl=en
* improve robustness on handling migratetype - 1 messages, 1 author
http://groups.google.com/group/linux.kernel/t/f7b811032da6c529?hl=en
* mm + fs: prepare for non-page entries in page cache radix trees - 3 messages,
1 author
http://groups.google.com/group/linux.kernel/t/8cc6f8a99500ab70?hl=en
* [PATCH] ASoC: simple-card: fix one bug to writing to the platform data - 1
messages, 1 author
http://groups.google.com/group/linux.kernel/t/90c1738a8c30a457?hl=en
* linux-next: manual merge of the mmc tree with Linus' tree - 1 messages, 1
author
http://groups.google.com/group/linux.kernel/t/925ee3315437b5d5?hl=en
* mm/swap: fix race on swap_info reuse between swapoff and swapon - 3 messages,
2 authors
http://groups.google.com/group/linux.kernel/t/c7226daad86a019b?hl=en
* x86, mpx: extend siginfo structure to include bound violation information -
2 messages, 1 author
http://groups.google.com/group/linux.kernel/t/f580cf37a477f810?hl=en
* linux-next: manual merge of the tip tree with the net-next tree - 2 messages,
1 author
http://groups.google.com/group/linux.kernel/t/ec246d2e3d0c7bcd?hl=en
* ARM: imx: add select on ARCH_MXC for cpufreq support - 1 messages, 1 author
http://groups.google.com/group/linux.kernel/t/ac37cf733bfa1109?hl=en
* linux-next: manual merge of the tip tree with the xtensa tree - 3 messages,
2 authors
http://groups.google.com/group/linux.kernel/t/8bb6a3eec699d1bd?hl=en
* cpufreq: imx6q-cpufreq driver depends on SOC_IMX6Q/SOC_IMX6SL - 1 messages,
1 author
http://groups.google.com/group/linux.kernel/t/bcd47c6a38b462f7?hl=en
* linux-next: manual merge of the tip tree with the pm tree - 1 messages, 1
author
http://groups.google.com/group/linux.kernel/t/3889209528ed13c6?hl=en
* qrwlock: Use smp_store_release() in write_unlock() - 2 messages, 2 authors
http://groups.google.com/group/linux.kernel/t/31f786da5ce84591?hl=en
* next bio iters break discard? - 1 messages, 1 author
http://groups.google.com/group/linux.kernel/t/df8973f865430413?hl=en
==============================================================================
TOPIC: video: add OpenCores VGA/LCD framebuffer driver
http://groups.google.com/group/linux.kernel/t/6de4648d5dffb42a?hl=en
==============================================================================
== 1 of 1 ==
Date: Sun, Jan 12 2014 5:30 pm
From: Jingoo Han
On Saturday, January 11, 2014 5:13 AM, Stefan Kristiansson wrote:
>
> This adds support for the VGA/LCD core available from OpenCores:
> http://opencores.org/project,vga_lcd
>
> The driver have been tested together with both OpenRISC and
> ARM (socfpga) processors.
>
> Signed-off-by: Stefan Kristiansson <stefan.kristiansson@saunalahti.fi>
> ---
> Changes in v2:
> - Add Microblaze as an example user and fix a typo in Xilinx Zynq
>
> Changes in v3:
> - Use devm_kzalloc instead of kzalloc
> - Remove superflous MODULE #ifdef
>
> Changes in v4:
> - Remove 'default n' in Kconfig
> - Simplify ioremap/request_mem_region by using devm_ioremap_resource
> - Remove release_mem_region
>
> Changes in v5:
> - Remove static structs to support multiple devices
> ---
> drivers/video/Kconfig | 16 ++
> drivers/video/Makefile | 1 +
> drivers/video/ocfb.c | 440 +++++++++++++++++++++++++++++++++++++++++++++++++
> 3 files changed, 457 insertions(+)
> create mode 100644 drivers/video/ocfb.c
It looks good.
However, I added some minor comments. :-)
Sorry for late response.
[.....]
> +#include <linux/module.h>
> +#include <linux/kernel.h>
> +#include <linux/errno.h>
> +#include <linux/string.h>
> +#include <linux/slab.h>
> +#include <linux/delay.h>
> +#include <linux/mm.h>
> +#include <linux/dma-mapping.h>
> +#include <linux/fb.h>
> +#include <linux/init.h>
> +#include <linux/io.h>
> +#include <linux/platform_device.h>
> +#include <linux/of.h>
Would you re-order these headers alphabetically?
It enhances the readability.
[.....]
> +struct ocfb_dev {
> + struct fb_info info;
> + void __iomem *regs;
> + /* flag indicating whether the regs are little endian accessed */
> + int little_endian;
> + /* Physical and virtual addresses of framebuffer */
> + phys_addr_t fb_phys;
> + void __iomem *fb_virt;
> + u32 pseudo_palette[PALETTE_SIZE];
> +};
Here, 'fb_virt' is already defined as 'void __iomem *'.
[.....]
> + fbdev->info.fix.smem_start = fbdev->fb_phys;
> + fbdev->info.screen_base = (void __iomem *)fbdev->fb_virt;
Please remove unnecessary casting as below, because 'fb_virt' is already
defined as 'void __iomem *'.
+ fbdev->info.screen_base = fbdev->fb_virt;
> + fbdev->info.pseudo_palette = fbdev->pseudo_palette;
> +
> + /* Clear framebuffer */
> + memset_io((void __iomem *)fbdev->fb_virt, 0, fbsize);
Same here.
+ memset_io(fbdev->fb_virt, 0, fbsize);
Best regards,
Jingoo Han
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
==============================================================================
TOPIC: re-shrink 'struct page' when SLUB is on.
http://groups.google.com/group/linux.kernel/t/d6d1692f51c2de27?hl=en
==============================================================================
== 1 of 2 ==
Date: Sun, Jan 12 2014 5:50 pm
From: Joonsoo Kim
On Sat, Jan 11, 2014 at 06:55:39PM -0600, Christoph Lameter wrote:
> On Sat, 11 Jan 2014, Pekka Enberg wrote:
>
> > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <dave@sr71.net> wrote:
> > > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> > >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> > >>> with my new slub code (all single-threaded):
> > >>>
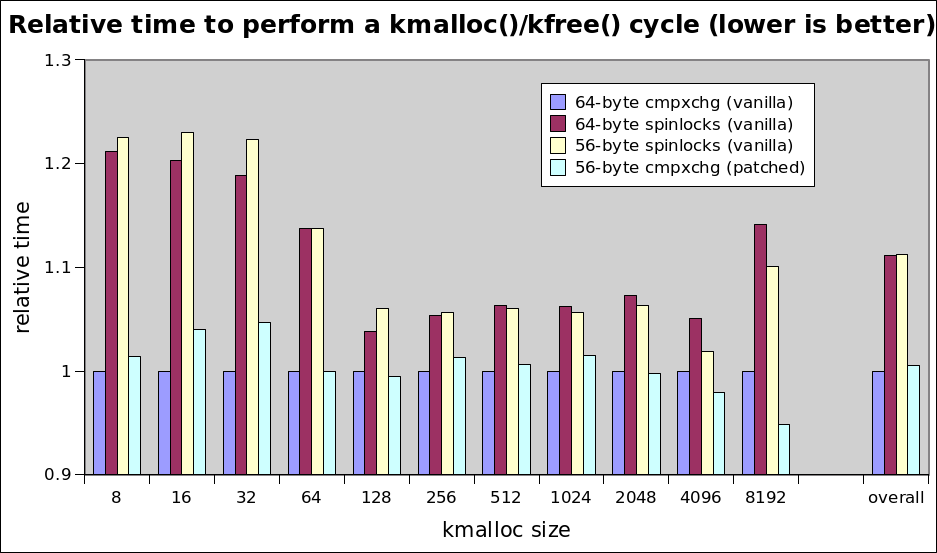
> > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> > >>
> > >> So we're converging on the most complex option. argh.
> > >
> > > Yeah, looks that way.
> >
> > Seems like a reasonable compromise between memory usage and allocation speed.
> >
> > Christoph?
>
> Fundamentally I think this is good. I need to look at the details but I am
> only going to be able to do that next week when I am back in the office.
Hello,
I have another guess about the performance result although I didn't look at
these patches in detail. I guess that performance win of 64-byte sturct on
small allocations can be caused by low latency when accessing slub's metadata,
that is, struct page.
Following is pages per slab via '/proc/slabinfo'.
size pages per slab
...
256 1
512 1
1024 2
2048 4
4096 8
8192 8
We only touch one struct page on small allocation.
In 64-byte case, we always use one cacheline for touching struct page, since
it is aligned to cacheline size. However, in 56-byte case, we possibly use
two cachelines because struct page isn't aligned to cacheline size.
This aspect can change on large allocation cases. For example, consider
4096-byte allocation case. In 64-byte case, it always touches 8 cachelines
for metadata, however, in 56-byte case, it touches 7 or 8 cachelines since
8 struct page occupies 8 * 56 bytes memory, that is, 7 cacheline size.
This guess may be wrong, so if you think it wrong, please ignore it. :)
And I have another opinion on this patchset. Diminishing struct page size
will affect other usecases beside the slub. As we know, Dave found this
by doing sequential 'dd'. I think that it may be the best case for 56-byte case.
If we randomly touch the struct page, this un-alignment can cause regression
since touching the struct page will cause two cachline misses. So, I think
that it is better to get more benchmark results to this patchset for convincing
ourselves. If possible, how about asking Fengguang to run whole set of
his benchmarks before going forward?
Thanks.
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
== 2 of 2 ==
Date: Sun, Jan 12 2014 7:40 pm
From: Davidlohr Bueso
On Mon, 2014-01-13 at 10:44 +0900, Joonsoo Kim wrote:
> On Sat, Jan 11, 2014 at 06:55:39PM -0600, Christoph Lameter wrote:
> > On Sat, 11 Jan 2014, Pekka Enberg wrote:
> >
> > > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <dave@sr71.net> wrote:
> > > > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> > > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> > > >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> > > >>> with my new slub code (all single-threaded):
> > > >>>
> > > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> > > >>
> > > >> So we're converging on the most complex option. argh.
> > > >
> > > > Yeah, looks that way.
> > >
> > > Seems like a reasonable compromise between memory usage and allocation speed.
> > >
> > > Christoph?
> >
> > Fundamentally I think this is good. I need to look at the details but I am
> > only going to be able to do that next week when I am back in the office.
>
> Hello,
>
> I have another guess about the performance result although I didn't look at
> these patches in detail. I guess that performance win of 64-byte sturct on
> small allocations can be caused by low latency when accessing slub's metadata,
> that is, struct page.
>
> Following is pages per slab via '/proc/slabinfo'.
>
> size pages per slab
> ...
> 256 1
> 512 1
> 1024 2
> 2048 4
> 4096 8
> 8192 8
>
> We only touch one struct page on small allocation.
> In 64-byte case, we always use one cacheline for touching struct page, since
> it is aligned to cacheline size. However, in 56-byte case, we possibly use
> two cachelines because struct page isn't aligned to cacheline size.
>
> This aspect can change on large allocation cases. For example, consider
> 4096-byte allocation case. In 64-byte case, it always touches 8 cachelines
> for metadata, however, in 56-byte case, it touches 7 or 8 cachelines since
> 8 struct page occupies 8 * 56 bytes memory, that is, 7 cacheline size.
>
> This guess may be wrong, so if you think it wrong, please ignore it. :)
>
> And I have another opinion on this patchset. Diminishing struct page size
> will affect other usecases beside the slub. As we know, Dave found this
> by doing sequential 'dd'. I think that it may be the best case for 56-byte case.
> If we randomly touch the struct page, this un-alignment can cause regression
> since touching the struct page will cause two cachline misses. So, I think
> that it is better to get more benchmark results to this patchset for convincing
> ourselves. If possible, how about asking Fengguang to run whole set of
> his benchmarks before going forward?
Cc'ing him.
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
==============================================================================
TOPIC: linux-next: manual merge of the sound-asoc tree with the slave-dma tree
http://groups.google.com/group/linux.kernel/t/6e92e09529c4927c?hl=en
==============================================================================
== 1 of 1 ==
Date: Sun, Jan 12 2014 5:50 pm
From: Stephen Rothwell
Hi all,
Today's linux-next merge of the sound-asoc tree got a conflict in
sound/soc/fsl/fsl_ssi.c between commit 0da9e55e71bc ("ASoC: fsl_ssi: Add
dual fifo mode support") from the slave-dma tree and commit 2b56b5f02029
("ASoC: fsl_ssi: Set default slot number for common cases") from the
sound-asoc tree.
I fixed it up (see below) and can carry the fix as necessary (no action
is required).
--
Cheers,
Stephen Rothwell sfr@canb.auug.org.au
diff --cc sound/soc/fsl/fsl_ssi.c
index 2101fc5c5739,7864ec5cf5f9..000000000000
--- a/sound/soc/fsl/fsl_ssi.c
+++ b/sound/soc/fsl/fsl_ssi.c
@@@ -140,8 -162,9 +162,10 @@@ struct fsl_ssi_private
bool ssi_on_imx;
bool imx_ac97;
bool use_dma;
+ bool use_dual_fifo;
bool baudclk_locked;
+ bool irq_stats;
+ bool offline_config;
u8 i2s_mode;
spinlock_t baudclk_lock;
struct clk *baudclk;
@@@ -421,12 -711,17 +712,23 @@@ static int fsl_ssi_setup(struct fsl_ssi
if (ssi_private->imx_ac97)
fsl_ssi_setup_ac97(ssi_private);
+ if (ssi_private->use_dual_fifo) {
+ write_ssi_mask(&ssi->srcr, 0, CCSR_SSI_SRCR_RFEN1);
+ write_ssi_mask(&ssi->stcr, 0, CCSR_SSI_STCR_TFEN1);
+ write_ssi_mask(&ssi->scr, 0, CCSR_SSI_SCR_TCH_EN);
+ }
+
+ /*
+ * Set a default slot number so that there is no need for those common
+ * cases like I2S mode to call the extra set_tdm_slot() any more.
+ */
+ if (!ssi_private->imx_ac97) {
+ write_ssi_mask(&ssi->stccr, CCSR_SSI_SxCCR_DC_MASK,
+ CCSR_SSI_SxCCR_DC(2));
+ write_ssi_mask(&ssi->srccr, CCSR_SSI_SxCCR_DC_MASK,
+ CCSR_SSI_SxCCR_DC(2));
+ }
+
return 0;
}
@@@ -1170,8 -1343,35 +1359,35 @@@ static int fsl_ssi_probe(struct platfor
ssi_private->baudclk_locked = false;
spin_lock_init(&ssi_private->baudclk_lock);
- if (of_device_is_compatible(pdev->dev.of_node, "fsl,imx21-ssi")) {
+ /*
+ * imx51 and later SoCs have a slightly different IP that allows the
+ * SSI configuration while the SSI unit is running.
+ *
+ * More important, it is necessary on those SoCs to configure the
+ * sperate TX/RX DMA bits just before starting the stream
+ * (fsl_ssi_trigger). The SDMA unit has to be configured before fsl_ssi
+ * sends any DMA requests to the SDMA unit, otherwise it is not defined
+ * how the SDMA unit handles the DMA request.
+ *
+ * SDMA units are present on devices starting at imx35 but the imx35
+ * reference manual states that the DMA bits should not be changed
+ * while the SSI unit is running (SSIEN). So we support the necessary
+ * online configuration of fsl-ssi starting at imx51.
+ */
+ switch (hw_type) {
+ case FSL_SSI_MCP8610:
+ case FSL_SSI_MX21:
+ case FSL_SSI_MX35:
+ ssi_private->offline_config = true;
+ break;
+ case FSL_SSI_MX51:
+ ssi_private->offline_config = false;
+ break;
+ }
+
+ if (hw_type == FSL_SSI_MX21 || hw_type == FSL_SSI_MX51 ||
+ hw_type == FSL_SSI_MX35) {
- u32 dma_events[2];
+ u32 dma_events[2], dmas[4];
ssi_private->ssi_on_imx = true;
ssi_private->clk = devm_clk_get(&pdev->dev, NULL);
@@@ -1234,16 -1435,13 +1451,22 @@@
dma_events[0], shared ? IMX_DMATYPE_SSI_SP : IMX_DMATYPE_SSI);
imx_pcm_dma_params_init_data(&ssi_private->filter_data_rx,
dma_events[1], shared ? IMX_DMATYPE_SSI_SP : IMX_DMATYPE_SSI);
+ if (!of_property_read_u32_array(pdev->dev.of_node, "dmas", dmas, 4)
+ && dmas[2] == IMX_DMATYPE_SSI_DUAL) {
+ ssi_private->use_dual_fifo = true;
+ /* When using dual fifo mode, we need to keep watermark
+ * as even numbers due to dma script limitation.
+ */
+ ssi_private->dma_params_tx.maxburst &= ~0x1;
+ ssi_private->dma_params_rx.maxburst &= ~0x1;
+ }
- } else if (ssi_private->use_dma) {
+ }
+
+ /*
+ * Enable interrupts only for MCP8610 and MX51. The other MXs have
+ * different writeable interrupt status registers.
+ */
+ if (ssi_private->use_dma) {
/* The 'name' should not have any slashes in it. */
ret = devm_request_irq(&pdev->dev, ssi_private->irq,
fsl_ssi_isr, 0, ssi_private->name,
==============================================================================
TOPIC: improve robustness on handling migratetype
http://groups.google.com/group/linux.kernel/t/f7b811032da6c529?hl=en
==============================================================================
== 1 of 1 ==
Date: Sun, Jan 12 2014 6:00 pm
From: Joonsoo Kim
On Fri, Jan 10, 2014 at 09:48:34AM +0000, Mel Gorman wrote:
> On Fri, Jan 10, 2014 at 05:48:55PM +0900, Joonsoo Kim wrote:
> > On Thu, Jan 09, 2014 at 09:27:20AM +0000, Mel Gorman wrote:
> > > On Thu, Jan 09, 2014 at 04:04:40PM +0900, Joonsoo Kim wrote:
> > > > Hello,
> > > >
> > > > I found some weaknesses on handling migratetype during code review and
> > > > testing CMA.
> > > >
> > > > First, we don't have any synchronization method on get/set pageblock
> > > > migratetype. When we change migratetype, we hold the zone lock. So
> > > > writer-writer race doesn't exist. But while someone changes migratetype,
> > > > others can get migratetype. This may introduce totally unintended value
> > > > as migratetype. Although I haven't heard of any problem report about
> > > > that, it is better to protect properly.
> > > >
> > >
> > > This is deliberate. The migratetypes for the majority of users are advisory
> > > and aimed for fragmentation avoidance. It was important that the cost of
> > > that be kept as low as possible and the general case is that migration types
> > > change very rarely. In many cases, the zone lock is held. In other cases,
> > > such as splitting free pages, the cost is simply not justified.
> > >
> > > I doubt there is any amount of data you could add in support that would
> > > justify hammering the free fast paths (which call get_pageblock_type).
> >
> > Hello, Mel.
> >
> > There is a possibility that we can get unintended value such as 6 as migratetype
> > if reader-writer (get/set pageblock_migratetype) race happends. It can be
> > possible, because we read the value without any synchronization method. And
> > this migratetype, 6, has no place in buddy freelist, so array index overrun can
> > be possible and the system can break, although I haven't heard that it occurs.
> >
> > I think that my solution is too expensive. However, I think that we need
> > solution. aren't we? Do you have any better idea?
> >
>
> It's not something I have ever heard or seen of occurring but
> if you've identified that it's a real possibility then split
> get_pageblock_migratetype into locked and unlocked versions. Ensure
> that calls to set_pageblock_migratetype is always under zone->lock and
> get_pageblock_migratetype is also under zone->lock which both should be
> true in the majority of cases. Use the unlocked version otherwise but
> instead of synchronoing, check if it's returning >= MIGRATE_TYPES and
> return MIGRATE_MOVABLE in the unlikely event of a race. This will avoid
> harming the fast paths for the majority of users and limit the damage if
> a MIGRATE_CMA region is accidentally treated as MIGRATe_MOVABLE
Okay.
I will re-investigate it and if I have indentified that it's a real possiblity,
I will re-make this patch according to your advice.
Thanks for comment!
--
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@vger.kernel.org
More majordomo info at http://vger.kernel.org/majordomo-info.html
Please read the FAQ at http://www.tux.org/lkml/
==============================================================================
TOPIC: mm + fs: prepare for non-page entries in page cache radix trees
http://groups.google.com/group/linux.kernel/t/8cc6f8a99500ab70?hl=en
==============================================================================
== 1 of 3 ==
Date: Sun, Jan 12 2014 6:10 pm
From: Minchan Kim
On Fri, Jan 10, 2014 at 01:10:39PM -0500, Johannes Weiner wrote:
> shmem mappings already contain exceptional entries where swap slot
> information is remembered.
>
> To be able to store eviction information for regular page cache,
> prepare every site dealing with the radix trees directly to handle
> entries other than pages.
>
> The common lookup functions will filter out non-page entries and
> return NULL for page cache holes, just as before. But provide a raw
> version of the API which returns non-page entries as well, and switch
> shmem over to use it.
>
> Signed-off-by: Johannes Weiner <hannes@cmpxchg.org>
Reviewed-by: Minchan Kim <minchan@kernel.org>
Below are just nitpicks.
> ---
> fs/btrfs/compression.c | 2 +-
> include/linux/mm.h | 8 ++
> include/linux/pagemap.h | 15 ++--
> include/linux/pagevec.h | 3 +
> include/linux/shmem_fs.h | 1 +
> mm/filemap.c | 196 +++++++++++++++++++++++++++++++++++++++++------
> mm/mincore.c | 20 +++--
> mm/readahead.c | 2 +-
> mm/shmem.c | 97 +++++------------------
> mm/swap.c | 47 ++++++++++++
> mm/truncate.c | 73 ++++++++++++++----
> 11 files changed, 336 insertions(+), 128 deletions(-)
>
> diff --git a/fs/btrfs/compression.c b/fs/btrfs/compression.c
> index 6aad98cb343f..c88316587900 100644
> --- a/fs/btrfs/compression.c
> +++ b/fs/btrfs/compression.c
> @@ -474,7 +474,7 @@ static noinline int add_ra_bio_pages(struct inode *inode,
> rcu_read_lock();
> page = radix_tree_lookup(&mapping->page_tree, pg_index);
> rcu_read_unlock();
> - if (page) {
> + if (page && !radix_tree_exceptional_entry(page)) {
> misses++;
> if (misses > 4)
> break;
> diff --git a/include/linux/mm.h b/include/linux/mm.h
> index 8b6e55ee8855..c09ef3ae55bc 100644
> --- a/include/linux/mm.h
> +++ b/include/linux/mm.h
> @@ -906,6 +906,14 @@ extern void show_free_areas(unsigned int flags);
> extern bool skip_free_areas_node(unsigned int flags, int nid);
>
> int shmem_zero_setup(struct vm_area_struct *);
> +#ifdef CONFIG_SHMEM
> +bool shmem_mapping(struct address_space *mapping);
> +#else
> +static inline bool shmem_mapping(struct address_space *mapping)
> +{
> + return false;
> +}
> +
posted by twitter @ 12:11 AM
0 Comments
![]()

{kind=link}
0 Comments:
Post a Comment
Subscribe to Post Comments [Atom]
<< Home